
Cloud Setup Guide#
Note
The guidance below assumes you are not operating within a corporate network or under organization-specific policies. It provides instructions for onboarding directly a non-restricted GCP project.
If your company or lab uses custom IAM roles, security policies, infrastructure management tools, or other internal systems, please refer to your internal documentation for how those may apply alongside the steps outlined here.
For more detailed information on meeting the prerequisites, refer to the official GCP documentation.
GCP Project Setup Guide#
A GCP account with billing enabled.
Created a GCP project.
Get
roles/editoraccess to the GCP projectEnabled the necessary APIs on your GCP project:
Created GCS bucket(s) for storing assets. You need to create two different buckets for storing temporary and permanent assets. We will reference these as
temp_assets_bucket, andperm_assets_bucketrespectively throughout the library.Pro-tip: Create regional buckets and use the same region for all your resources and compute to keep your cloud costs minimal i.e.
us-central1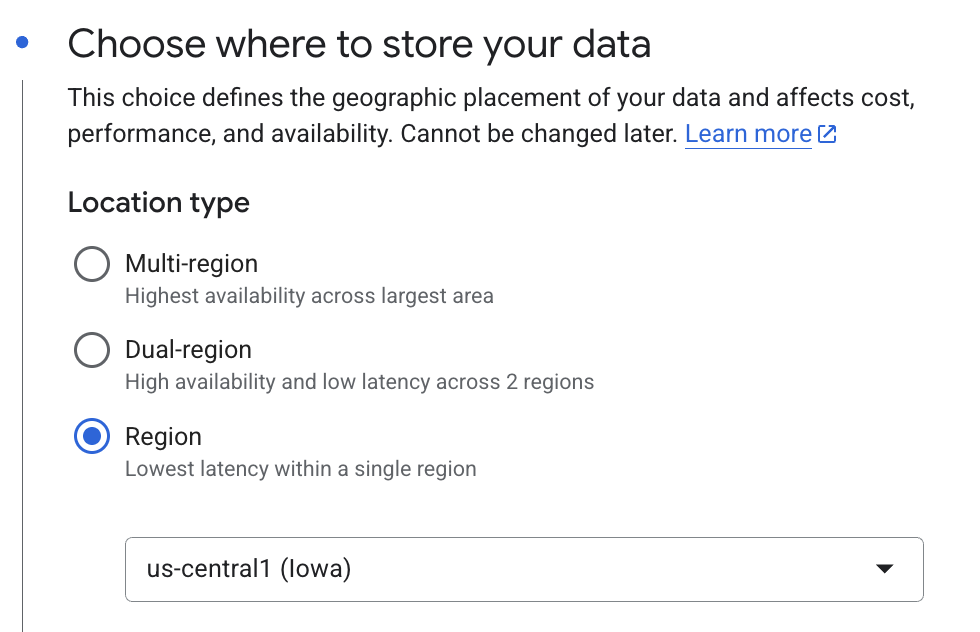
Ensure to use the “standard” default class for storage
(Optional) Enable Hierarchical namespace on this bucket
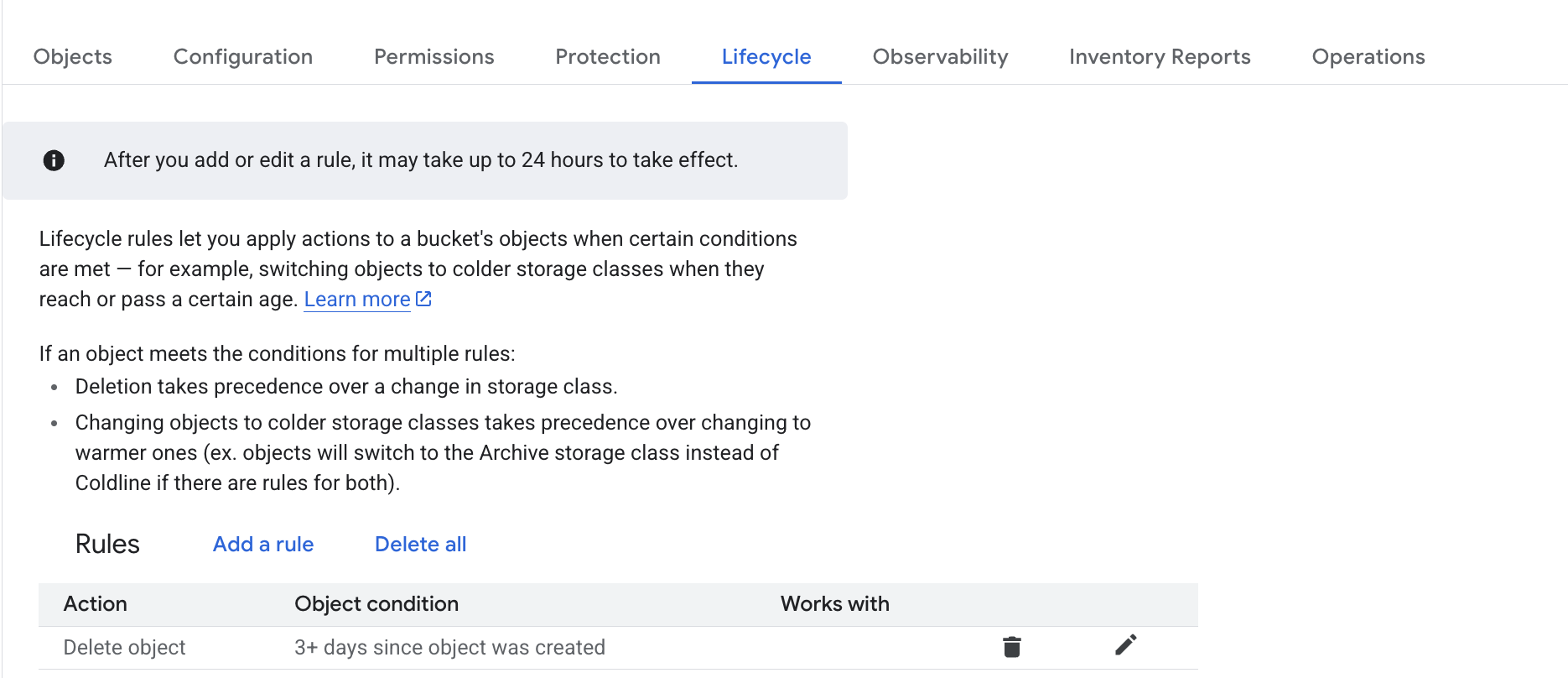
For your temp bucket its okay to disable
Soft delete policy (For data recovery), otherwise you will get billed unnecessarily for large amounts of intermediary assets GiGL creates.Since GiGL creates a lot of intermediary assets you will want to create a lifecycle rule on the temporary bucket to automatically delete assets. Intermediary assets can add up very quickly. Example:
Create BQ Datasets for storing assets. You need to create two different BQ datasets in the project, one for storing temporary assets, and one for output embeddings. We will reference these as
temp_assets_bq_dataset_name, andembedding_bq_dataset_namerespectively throughout the library.Caution
The BQ datasets must be in the same project and be multi regional with the location being the country/superset region where you plan on running the pipelines - otherwise pipelines won’t work. i.e.
us-central1region maps toUSfor multi_regional dataset.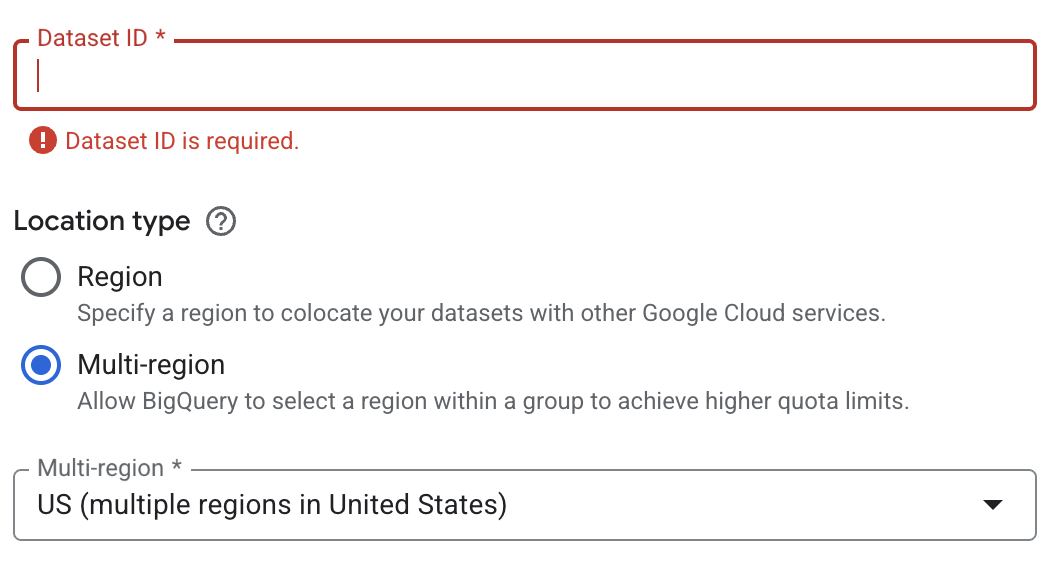
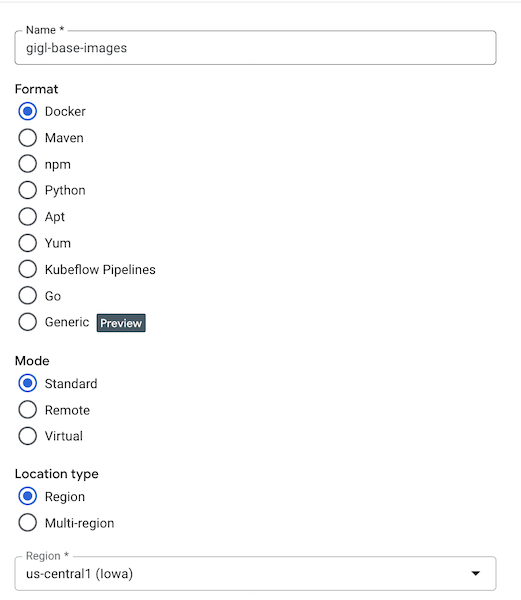
Create a Docker Artifact Registry for storing your compiled docker images that will contain your custom source code GiGL source. Ensure the registry is in the same region as your other compute assets.
Create a new GCP service account (or use an existing), and give it relevant IAM perms:
Note
You youself are going to need the following permissions to create new IAM bindings: roles/resourcemanager.projectIamAdmin, and roles/iam.serviceAccountAdmin
a. Firstly give the SA permission to use itself:
gcloud iam service-accounts add-iam-policy-binding $SERVICE_ACCOUNT \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/iam.serviceAccountUser"
b. Next, the SA will need some permissions at the project level:
Note
Example of granting bigquery.user:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/bigquery.user"
bigquery.usercloudprofiler.usercompute.admindataflow.admindataflow.workerdataproc.editorlogging.logWritermonitoring.metricWriternotebooks.legacyVieweraiplatform.userdataproc.workerartifactregistry.writer
c. Next we need to grant the GCP
Vertex AI Service Agent i.e.
service-$PROJECT_NUMBER@gcp-sa-aiplatform-cc.iam.gserviceaccount.com permissions to read from artifact registry so the
VAI pipelines can pull the docker images you push to the registry you created. You can get this by running:
gcloud projects describe $PROJECT_ID --format="value(projectNumber)"
Alternative, you can find your $PROJECT_NUMBER from your main project console page: console.cloud.google.com
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$PROJECT_NUMBER@gcp-sa-aiplatform-cc.iam.gserviceaccount.com" \
--role="roles/artifactregistry.reader"
Give your SA
storage.objectAdminandroles/storage.legacyBucketReaderon the buckets you created i.e. to grantstorage.objectAdminyou can run:
gcloud storage buckets add-iam-policy-binding $BUCKET_NAME \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/storage.objectAdmin"
Give your SA
roles/bigquery.dataOwneron the datasets you created. See instructions.
AWS Project Setup Guide#
Not yet supported